Kontrol og procesoverholdelse
Et af de områder, hvor AI og sprogmodeller for alvor har fundet anvendelse, er inden for kontrol, kvalitetssikring og procesopfølgning. Her findes der allerede en række veletablerede analysemetoder, som danner et naturligt udgangspunkt for det arbejde, AI kan udføre. En af de mest kendte er process mining, som typisk anvendes via specialiserede værktøjer. I denne tilgang er fokus ikke alene på de data, der er registreret i systemerne, men på selve den proces, hvormed dataene er blevet til.
Processen bag data er afgørende i mange sammenhænge, eksempelvis i relation til hvidvaskkontrol, compliance eller tidlig validering af data i samarbejdsforløb. Når datakilderne er mange og forskelligartede, kan det være vanskeligt løbende at sikre, at processerne fungerer som forudsat, og at data skabes korrekt. Traditionelt har dette krævet omfattende manuelle kontroller og efterfølgende vurderinger.
Tidligere har man ofte arbejdet med metoder som anomaly detection, hvor man scanner datasæt for ændringer eller afvigelser og derefter vurderer, om disse giver anledning til yderligere undersøgelse. I dag kan denne type arbejde i høj grad automatiseres ved hjælp af AI, hvor agenter selvstændigt kan udføre opfølgende kontroller eller dykke dybere ned i de områder, der fremstår usædvanlige.
Det betyder, at kontrol- og opfølgningsarbejdet i stigende grad kan automatiseres, og at organisationer kan bevæge sig fra stikprøvekontroller til reel, bred datakontrol. I stedet for kun at kontrollere udvalgte poster kan man gennemløbe hele datasæt eller store delmængder og dermed opnå en langt højere sikkerhed for, at data er skabt og behandlet som forventet.
Et af de mest oplagte anvendelsesområder er økonomiske transaktioner i regnskabssystemer. I store og komplekse organisationer kan regnskabsprocessen være vanskelig at styre, særligt når mange aktører arbejder parallelt i systemet. Med mange brugere opstår der ofte variation i måden, data registreres på, selv når der formelt er fastlagte retningslinjer. Det gør det udfordrende at sikre ensartet kontering, korrekt brug af momskoder, ensartede modtagelses- og nedskrivningsprocesser samt konsistens på tværs af konti og perioder.
Denne type kontrol egner sig særdeles godt til en AI-baseret assistent. Assistenten kan løbende analysere data i regnskabssystemet og kontrollere, om registreringerne følger den praksis, organisationen har defineret. I praksis kræver det, at assistenten etableres og trænes i forhold til netop den kontoplan, de konteringsprincipper og den forretningslogik, der gælder i det konkrete system. Selvom hovedkonti ofte ligner hinanden på tværs af organisationer, ligger den afgørende viden i detaljerne, og det er denne viden, der skal indarbejdes i modellen.
Når modellen først er etableret, handler resten primært om finjustering og løbende tilpasning. Herefter kan assistenten anvendes dagligt og selvstændigt identificere uhensigtsmæssigheder eller uklarheder, som bør følges op. Den kan eksempelvis automatisk kontakte relevante aktører for at indhente supplerende forklaringer, fortolke svarene og enten lukke sagen eller eskalere den til en medarbejder, hvis der er behov for menneskelig vurdering.
På den måde bliver kontrol og kvalitetssikring ikke længere en periodisk eller reaktiv disciplin, men en kontinuerlig proces, der bidrager til højere datakvalitet, bedre compliance og et mere robust beslutningsgrundlag i organisationen.
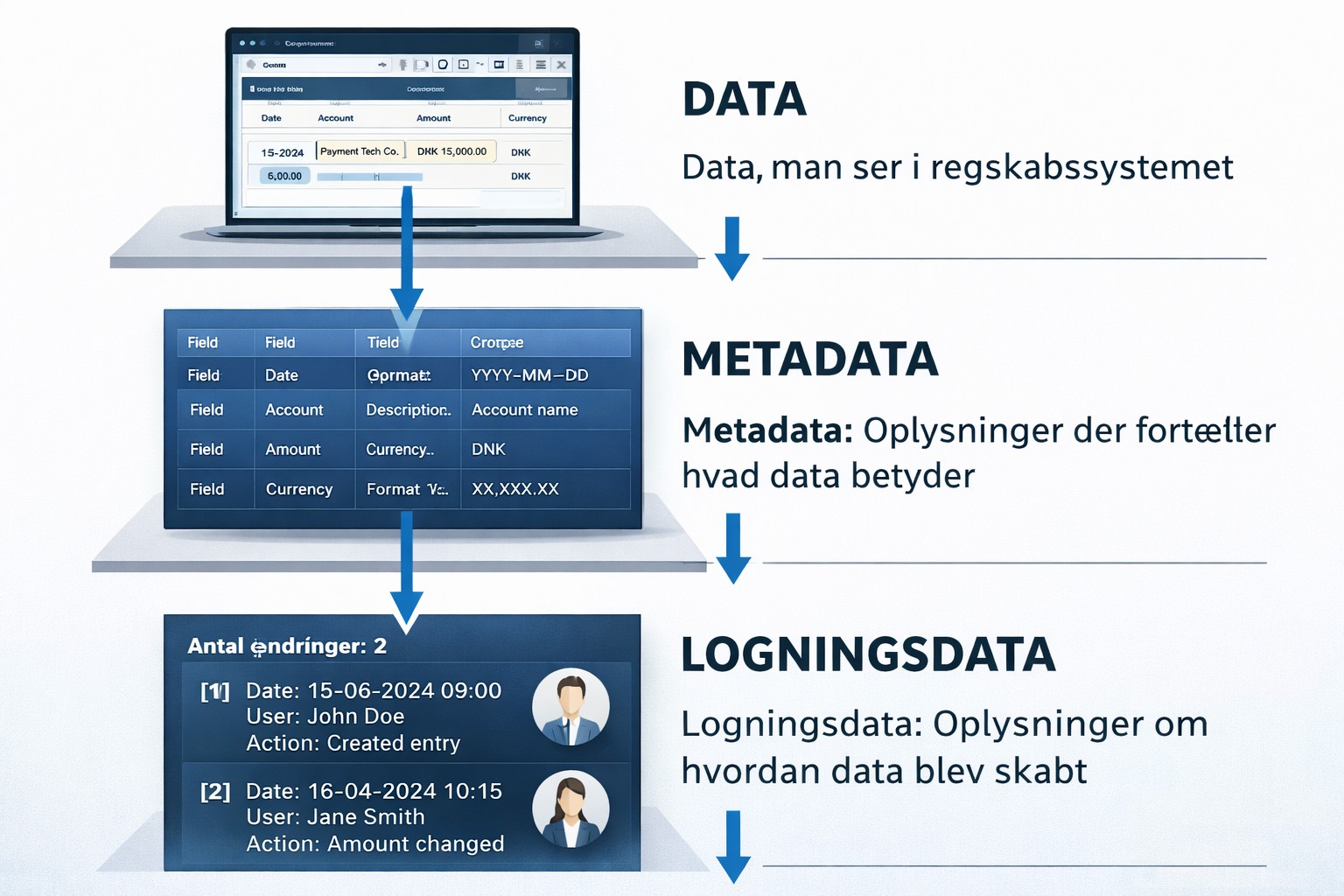 Hvordan gør man i praksis?
Hvordan gør man i praksis?
Først og fremmest er det afgørende at kende sine data og i disse opgaver især sine metadata – altså hvilke data der findes, og hvordan de er blevet skabt(metadata) - incl. både transaktions og autorisationslog. Denne type analyse kan ikke gennemføres alene på baggrund af udtræk fra økonomisystemet eller de rapporter, man normalt anvender. Den kræver adgang til de bagvedliggende transaktionsdata, hvem har skabt dem, hvornår og via hvilke værkøtjer.
Transaktionsdata kan i sig selv være vanskelige at læse, men med tilstrækkelige datamængder og adgang til det reelle forretningsflow bør enhver kompetent programmør kunne etablere et dataflow, der understøtter AI- eller LLM-arbejde.
En LLM er som udgangspunkt ikke en stærk regnemaskine. Derfor skal man undgå at arbejde med store, talintensive datasæt direkte. I stedet skal opgaver fragmenteres, og analyser bør gennemføres på enkelttransaktionsniveau. Analyserne bruger relativt mange tokens (regnekraft).
Når modellen er designet til at arbejde på niveauet for enkelte transaktioner, kan man igen udnytte LLM’ens styrke: evnen til at håndtere variationer i processer og forskellige veje gennem systemet. Det betyder, du laver en vej igennme, hvorefter din model selv kan designe den næste vej igennem osv. osv. Det er samtidig vigtigt, at man i dette arbejde fokusere og udnytte modellens evne til at sige fra, når den ikke forstår noget. Dette kan være en udfordring, da modellen altid forsøger at svare, men ved at formulere instrukser, hvor “jeg kan ikke komme videre” til at være en succes, får man hurtigt gode resultater og reele svar.